Containers technology

Kernel space and user space
In the article introducing the Containerization technology, and how it compares to the virtualization based on virtual machines, we saw how the hypervisor’s functionality was replaced by several features implemented directly in the host operating system’s kernel. Those features are used by the applications (containerized or not), as any other kernel feature, by calling its API through system calls. System calls can be invoked by any program running on the user space and they are fulfilled by the kernel in its kernel space, which is the protected operating system’s memory region where the kernel runs and provides its services. Those services are generally things that only the kernel has the privilege to do, such as doing I/O.
System calls and the communication between kernel and user spaces
When a container is started, a program is loaded into memory from the container image (we will see more on this later). Once the program in the container is running, it still needs to make system calls into kernel space. The ability for the user space and kernel space to communicate in a deterministic fashion is critical.
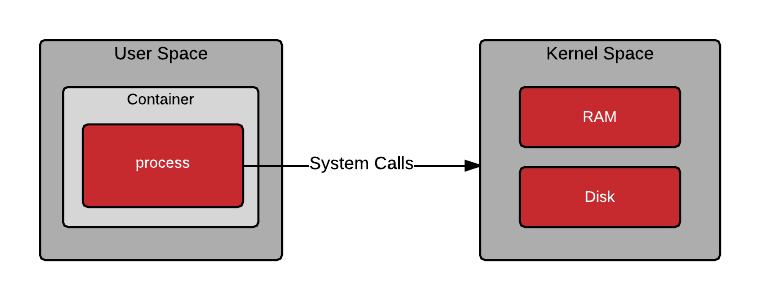 Communication between user space and kernel space
Communication between user space and kernel space
There are more than 300 system calls [2] supported by the Linux kernel and their definition can be seen here [4]. System calls can be used directly by the user applications, by the shell commands or through library routines as glibc.
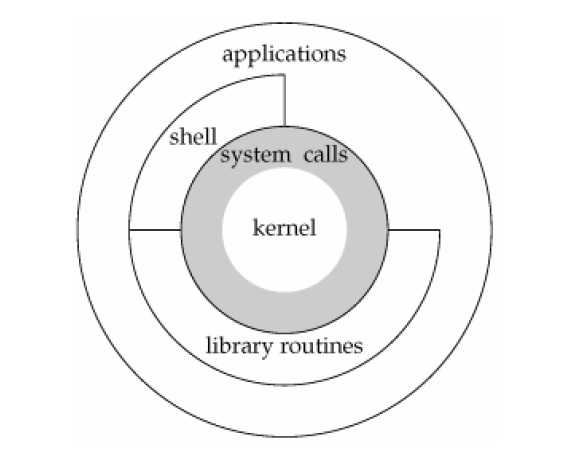 System calls and libraries
System calls and libraries
Among the features and their system calls used to support containers are: cgroups, chroot or namespaces.
-
chroot: mostly every UNIX operating system has the possibility to change the root directory of the current running process (and its children). This originates from the first occurrence of chroot in UNIX Version 7 (1979). Chroot is also referenced as “jail“. Nowadays chroot is not used by container runtimes any more and was replaced by
pivot_root(2), which has the benefit of putting the old mounts into a separate directory on calling. -
namespaces: namespaces are a Linux kernel feature which was introduced back in 2002 with Linux 2.4.19. The idea behind a namespace is to wrap certain global system resources in an abstraction layer. The kernel namespace abstraction allows different groups of processes to have different views of the system. Not all available namespaces were implemented from the beginning, a “container ready” version of those “virtualized kernel resources” was finished in kernel v3.8, back in 2013 with the introduction of the user namespace. Currently there are seven distinct namespaces implemented: mnt, pid, net, ipc, uts, user and cgroup [1].
-
cgroups: it started in 2008 with Linux 2.6.24 as dedicated Linux kernel feature and its main goal is to support resource limiting, prioritization, accounting and controlling. The second version of cgroups was released with v4.6 and included an Out-of-Memory (OoM) killer to kill a group of processes as a single unit to guarantee the overall integrity of the workload.
When a container is first instantiated, the user space of the container host makes system calls into the kernel to create special data structures in the kernel (cgroups, svirt, namespaces).
The following drawing shows when a container is created, the clone() system call
is used to create a new process. Clone is similar to fork, but allows the
new process to be set up within a kernel namespace. Kernel namespaces allow the
new process to have its own hostname, IP address, filesystem mount points,
process id, and more. A new name space can be created for each new container -
allowing them to each look and feel similar to a virtual machine [3].
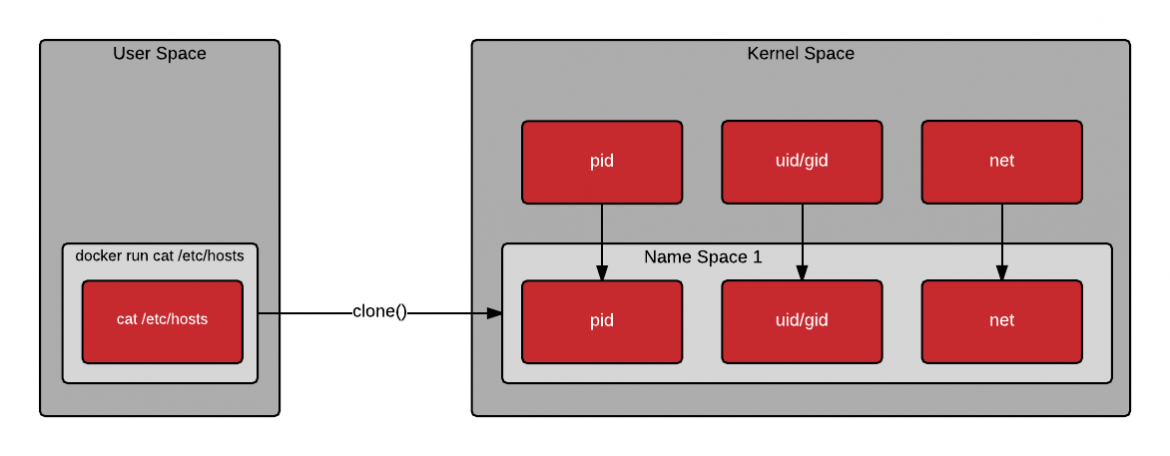 Creating a new container
Creating a new container
Once the container is instantiated, the process or processes execute within
a new user space created from mounting the container image. The processes inside
the container make system calls as they would normally. The kernel is responsible
for limiting what the processes in the container can do. Notice from the drawing
below, that the first command executes the open() system call directly from the
host’s user space, the second command executes the open() system call through
the mount namespace (containerized), and the third executes the getpid()
through the PID namespace (containerized).
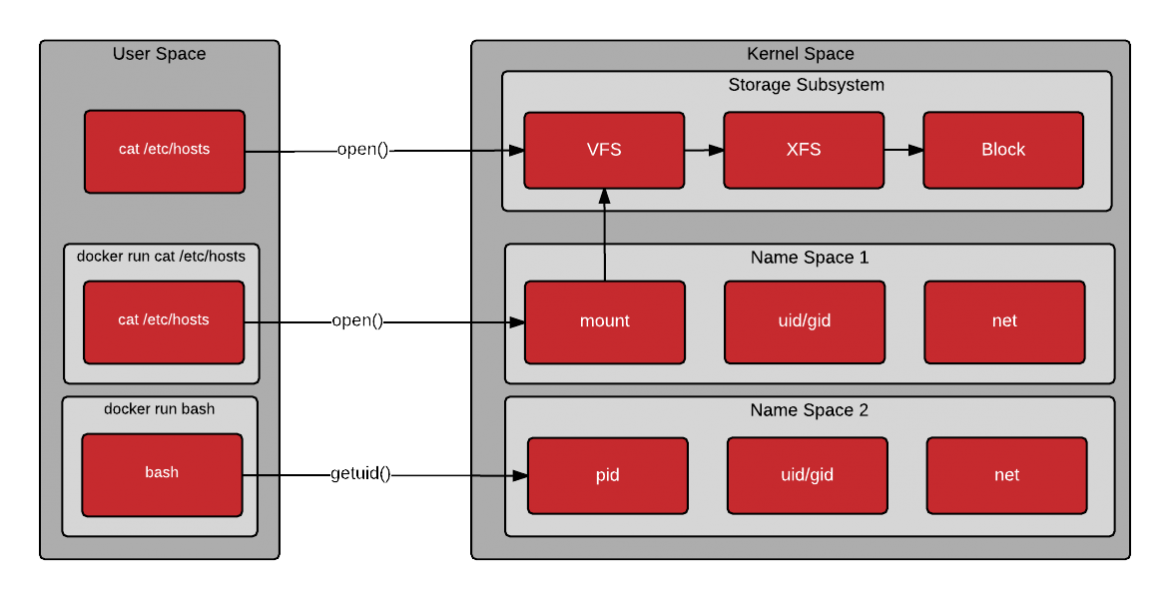 Creating a new container
Creating a new container
Container runtimes and container images
Leveraging on all the above kernel features to create containers is not easy, so it wasn’t until the advent on the project LXC (2007) when it became relatively easy to provide an isolated environment for running applications. LXC introduced the concept of Container Runtime which is basically a program able to run containers and at the same time it abstracts other programs from the complex interaction with the kernel through what is called Container Runtime API or Management Interface. The following picture illustrates that architecture.
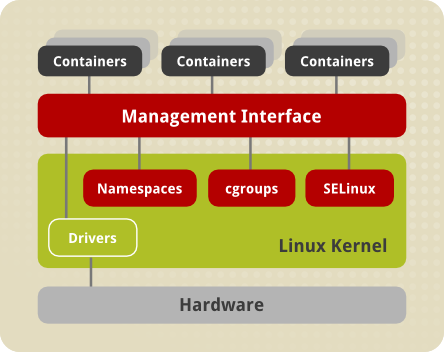 LXC Architecture
LXC Architecture
It should be noted that, as we can see by the types of system calls made by the Container Runtime, the performance of the low-level runtime is only significant during container creation or deletion. Once the process is running, the container runtime is out of the picture.
Although LXC eased the creation of containers it wasn’t very developer and user friendly, and that’s why Docker, began building tooling around LXC to make containers more easy to use. Docker created two important concepts that fostered the container ecosystem, the first one was the already mentioned Container Runtime and the second was the Container Image which was a very effective and portable way to pack application and services.
 Docker image structure
Docker image structure
The above image shows the fundamental components of any image-based container:
-
Container: an active component in which an application runs. Each container is based on an image that holds necessary configuration data. When you launch a container from an image, a writable layer is added on top of this image. Every time you commit a container (using i.e. the docker commit command), a new image layer is added to store your changes.
-
Image: a static snapshot of the containers’ configuration. Image is a read-only layer that is never modified, all changes are made in top-most writable layer, and can be saved only by creating a new image. Each image depends on one or more parent images.
-
Platform Image: an image that has no parent. Platform images define the runtime environment, packages and utilities necessary for a containerized application to run. The work with Docker usually starts by pulling the platform image. The platform image is read-only, so any changes are reflected in the copied images stacked on top of it.
In the following example [5] we can we specify the creation of a Docker image via
its Dockerfile:
FROM ubuntu:18.04
LABEL org.opencontainers.image.authors="org@example.com"
COPY . /app
RUN make /app
RUN rm -r $HOME/.cache
CMD python /app/app.py
The Dockerfile contains 4 commands. Commands that modify the filesystem create
a layer. The FROM statement starts out by creating a layer from the ubuntu:18.04
image. The LABEL command only modifies the image’s metadata, and does not
produce a new layer. The COPY command adds some files from your Docker client’s
current directory. The first RUN command builds your application using the make
command, and writes the result to a new layer. The second RUN command removes
a cache directory, and writes the result to a new layer. Finally, the CMD
instruction specifies what command to run within the container, which only modifies
the image’s metadata, which does not produce an image layer.
Each layer is only a set of differences from the layer before it. The layers are stacked on top of each other. When you create a new container, you add a new writable layer (Container layer) on top of the underlying layers. All changes made to the running container, such as writing new files, modifying existing files, and deleting files, are written to this thin writable container layer. The diagram below shows a container based on an ubuntu:15.04 image.
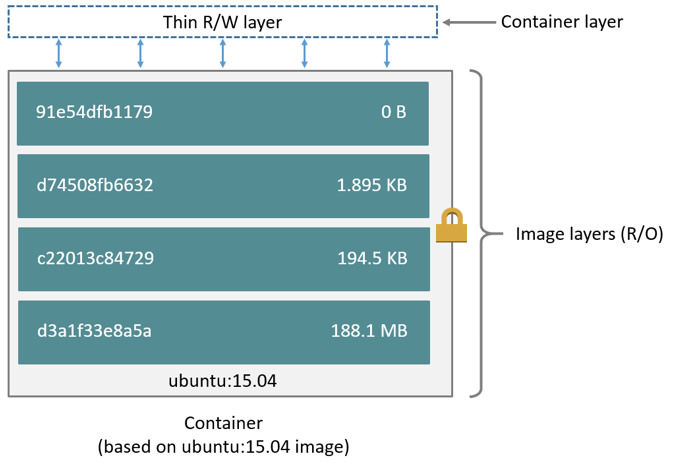 Container layers
Container layers
The major difference between a container and an image is the top writable layer. All writes to the container that add new or modify existing data are stored in this writable layer. When the container is deleted, the writable layer is also deleted. The underlying image remains unchanged.
Because each container has its own writable container layer, and all changes are stored in this container layer, multiple containers can share access to the same underlying image and yet have their own data state. The diagram below shows multiple containers sharing the same Ubuntu 15.04 image.
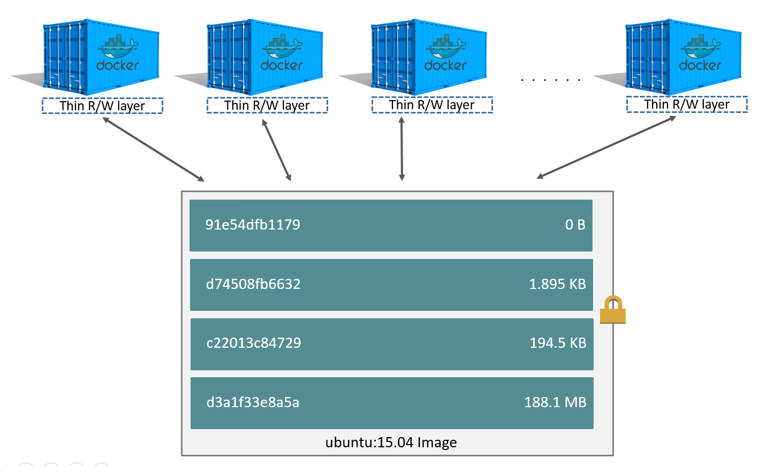 Sharing layers
Sharing layers
Standardization of Container Runtimes and Container Images
In 2015 Docker dropped LXC and started the Open Container Initiative (OCI) to stablish container standards and open sourced some of their container components as the libcontainer project. The OCI defines two main specifications:
- Runtime Specification (runtime-spec)
- Image Specification (image-spec)
The Runtime Specification outlines how to run a “filesystem bundle” that is unpacked on disk. At a high-level an OCI implementation would download an OCI Image then unpack that image into an OCI Runtime filesystem bundle. At this point the OCI Runtime Bundle would be run by an OCI Runtime.



